

Data as a Utility Tool
Data as a Utility Tool
Reasoning through a modern data analytics architecture

Welcome to group by 1. In this first post, I’ve started broad with my opinion on a few of the typical compromises made when implementing a modern data warehouse solution. Modern meaning cloud, data warehouse meaning the back-end for an analytics tool. This post is a primer for my future content.

Within the companies I have worked for and plan on working for, uncertainty is a common thread. Sales may continue to accelerate, funding should land next quarter, we hope to keep in touch. The uncertainty may be more concrete. We should change to a new CRM. We probably need to stop reporting in Excel.
I’ve put together some opinions on what has worked for me in managing uncertainty when architecting data systems that need to cater for many parallel futures.
Two Buckets
Designing solutions for analytics systems can stylistically or abstractly be described as a problem of two buckets. Bucket one is full of the typical problems a business might have. The business usually then approaches “the data team” with problems such as help us define a metric / store the data / visualise the KPI / distribute the report.
In this simplistic utopia, bucket two, the Solutions Bucket, is typically filled with lots of products and opinions, like Snowflake / Big Query / my last company used Tableau / group by 1 etc.
select * from problems_bucket
inner join (select * from solutions_bucket) 
The catch when architecting a solution is that you’re given only one scoop from the solution bucket, with the hope that it covers as many of the items in the problem bucket as possible. The solution bucket is usually very resource-intensive, expensive, time-consuming and gathers momentum once that scoop is moving.
The decision to re-scoop is not going to be taken lightly. The first scoop usually needs to be made under significant uncertainty and pressure. This is a time to be making bets that will serve you in many of your uncertain futures.
Travel Light
For this reason, I invoke the spirit of a prepper, where travelling light is as essential as being prepared. Enter the Swiss army knife.
My ideal scoop of the solution bucket, like a good utility tool, has a nice healthy mix of scalability, ease of use, and utilitarian functionality. Bare metal that stands the test of time and rests easily on the hip, ready for action!
More concretely, a lightweight data architecture describes modularity, where each component plays a specified part in the greater whole, without restricting the system. This enables upgrading, downgrading and replacing as necessary.
With that in mind, I’ll be describing my opinion / experience / preference for a utilitarian data architecture.
Context
The context of this article skews heavily to the typical first-hired-one-person-data-team scenario and is generally applicable if that person is within a small business, a startup or a small team within a larger organisation. It can be extended to a data team within a larger organisation that is rethinking their architecture.
New paradigms start from the ground up, and so it can safely be assumed that this paradigm will be what banks implement in 50 years while the rest of us use quantum computing to think the data into order.
The driver for this workflow arises from the need to centralise data across multiple systems, typically at the point where there are 3+ key business apps or systems.
If you're the one called in to take over from the last guy who burnt the ETL (extract-transform-load) candle on both ends and now has a 1000 yard stare, then this might hit a nerve.
Ingesting, Storing, Transforming, Distributing. Four verbs for four (4) sections that describe what will be covered, and the order.
1. Ingesting
I generally subscribe to the opinion that engineers should avoid writing custom ETL code whenever practically possible, and rather use a managed SaaS ETL tool. This resembles the corkscrew of our Swiss army knife. Powerful and simple.
Managed ETL tools allow you to connect to your supported sources, point those at your data warehouse and have data flowing in a matter of minutes. You are paying for specialisation here. Post-implementation, the ETL specialist at the end of an intercom is worth their (initially) nominal fee.

If you cannot get your data into your data warehouse with a managed ETL, or you cannot strike the cost/benefit balance, then you’ll have to start building. This is a great time to think about the possibility of contracting the work to a specialist. They’ll bring the expertise, and over time you can consider internalising that skill as you see fit. Because the work is narrowly described and easily measured, this is a great piece of work for outsourcing. Budget for a maintenance contract, and keep an eye on those Managed ETL services as a replacement option over time.
Some additional thoughts:
Ingesting raw data (JSON or tables) into your data warehouse is key. Don’t spend time at this point doing transforms in python, there isn’t time. ETL has been surpassed by ELT (extract-load-transform). This new paradigm is now established.
A Google sheet is a data source. Time is of the essence and done is better than perfect. Data validation, spreadsheet protection and read-only permissions do a database maketh. Use this one sparingly, as word may get out.
2. Storing
Balancing the trifecta of scalability, cost and performance is key when picking the backbone of your system. Your data may start small, or large, or small with a risk of growing large. Stopping to change a tire in bear country is never a good look, and neither is a data warehouse migration.
Managed data warehouses balance the trifecta, with scalability from a team of 1 to 100(n), megabytes to terabytes+, cost starting near zero, and performance flexibility to suit your budget and need.

Your contract for a data warehouse should begin near $0 and go up from there. Start negotiating your unit costs down once the value of the contract becomes significant, or sooner. The point is that you can get started, prove value, and iron out the details down the line.
Snowflake is a good start, Big Query does wonders. Microsoft is probably up to something with Azure. Redshift is squarely in the migrated_from category. All can scale beyond your VC backer's wildest dreams.
This is the knife of your Swiss army knife, simply put, a knife needs to be sharp, a data warehouse needs to be powerful. The main attraction.
3. Transforming
Pliers apply leverage. A Swiss army knife doesn’t have pliers, which is why no one owns one, preferring a utility-tool. Loosely applying the same logic, the Transformation Layer has long been the missing link in the analytics stack, with various frustrating attempts at enabling elegant management of transformations.

The broad goal here is to enable access to your data for your business users while abstracting away as much of the source system complexity as possible. The outcome is clean, documented, coherent, reliable, logical, self-explanatory and performant data that can be relied upon by the Distributing tools. This is the highest leverage point in your pipeline. Leverage that magnifies both gains and mistakes.
SQL is the language of analysis, and a collection of SQL scripts best describes the transformation of data landed RAW in your data warehouse to ultimately transformed and ready for ANALYTICS. The Analytics mentioned here is the schema that you expose to your Distributing tools.
Dataform is a tool that takes that simple concept and runs with it, making writing sophisticated transformations a delight for analysts. Simply explained, Dataform is a SQL editor that enables analysts to build complex transformations in a way that is maintainable and interpretable. Dataform is differentiated by three concepts from software engineering that are put in the hands of the analyst:
1/ Continuous Deployment
A deployment of new code or changes to your transforms should be a thing that happens continuously, and without fear. This is achieved through automated schema tests, continuously deploying code, and data validity and quality tests. This is achieved through the assertions in Dataform, among other useful features.
2/ Version Control
If your job involves writing SQL code, and doesn't involve version control, then perhaps more than anything else, this article was written for you.
3/ Modularity
If your SQL queries typically run into the 100's or 1000's of lines, with sub-queries galore, then breaking that into individual reusable modular components will feel like our man on a rock below. Extend this with JavaScript and suddenly you will be able to truly express yourself.

4. Distributing
### TODO - setup a BI tool
Distribution of data. Commonly described as an Analytics Tool or BI tool aka The Last Mile delivery problem.
In a physical product, and an analytics project, the last mile of delivery is often both the most expensive and time-consuming part of the delivery mechanism. This is the point where the surface area expands massively, and the usage pattern permutations explode. Bluntly; the neatly organised cookie-cutter data pipeline gets punched in the face by the needs of the user.
The utility-tool analogy falls apart somewhat at this point, as arguably the pliers should be used here. Just like this utility-tool, it can get a bit confusing.
Broadly speaking the distribution problem gets broken into two categories. BI tools and Analytics Tools. The distinction is murky, like your requirements. Generally speaking, these tools are either:
1/ Good at solving the operational reporting problems of business: Metrics, KPIs, lots of users, lots of operational complexity (tools like Looker, Metabase).
2/ Good at solving the analysts’ problems: complicated questions, nuanced analysis, vague outcomes, forecasts, predictions (tools like Mode, Periscope, Jupyter Notebooks).
A rule of thumb is that you need a good few business users who are comfortable writing complicated SQL or Python before Option 2 will be feasible. This decision is largely based on the operational complexity and technical fluency of the stakeholders in this grand adventure, and generally Option 1 is more broadly applicable.
If you’ve done good work in your Transforming layer, then you can get away with a compromise here, and use a cheaper tool as a stop-gap, or use an array of tools, or allow the team to choose whatever suits them. Ultimately, you want to trend towards a single source of truth for KPI / Metric type numbers, and aim to automate their delivery.
My experience
I've honed in on my preferred data stack, described below. This stack is likely a feasible option for your goals if they are related to aligning your business on key metrics. Especially so if you have multiple SaaS or custom software systems floating around that drive these metrics. What you’ll end up with is something like the following diagram.
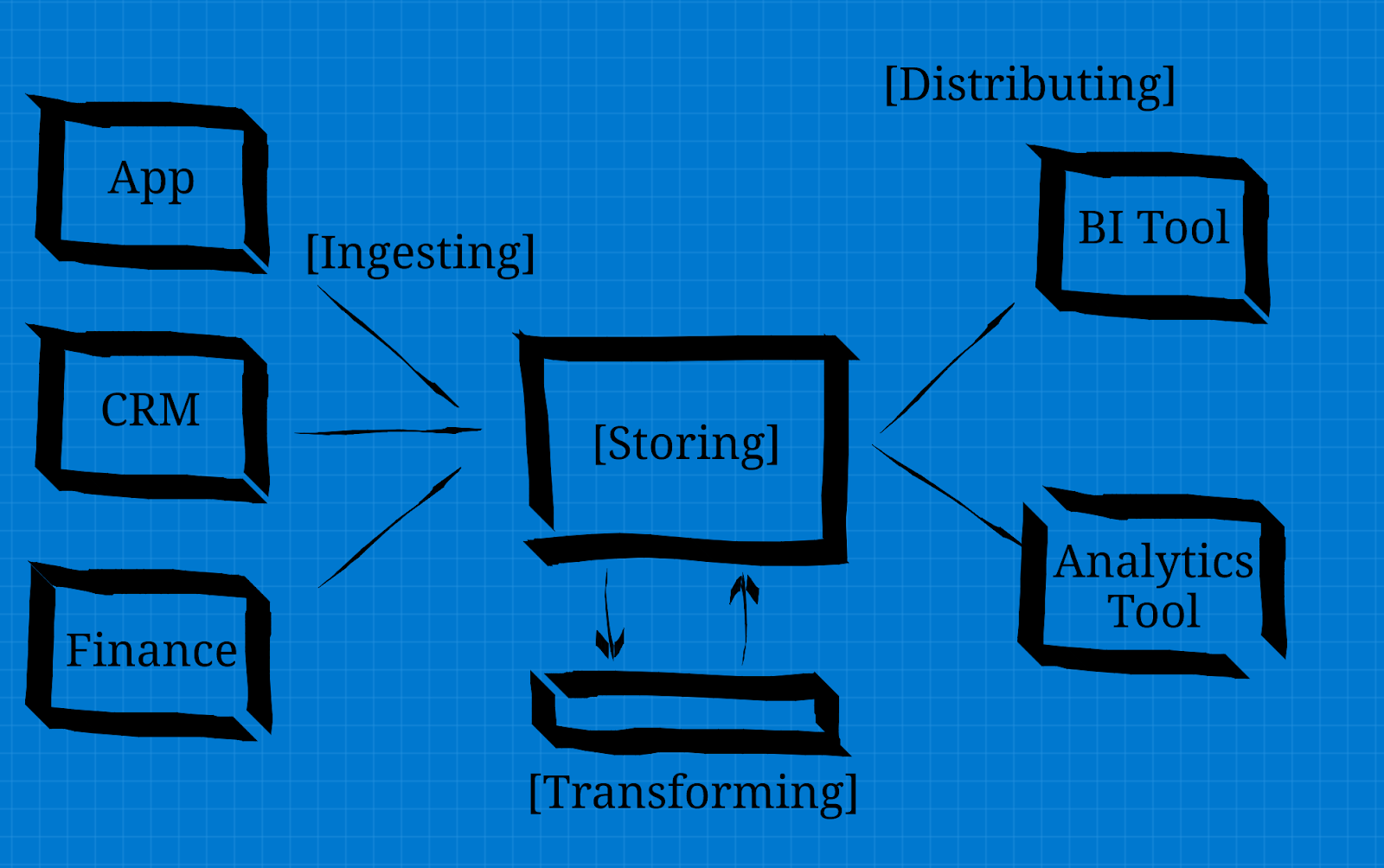
Ingesting/ As mentioned, I prefer to use a SaaS ELT tool like Stitch or Fivetran, as they reduce the need for ongoing maintenance where possible. Stitch is the cheaper option, and a great low-cost starting point, with the following useful additions:
It has a great Import API that allows some simplification of ELT scripts if you do need to write them.
It has a useful Google Sheets Integration, as well as the usual Postgres, Hubspot, Salesforce, Google/Facebook ads etc.
Storing/ The stack described orients towards BigQuery or Snowflake, with PostgreSQL also a feasible option. I prefer the scale / cost model of Snowflake.
Snowflake scales up to enterprise but starts from $2/credit, so can be a very cost-effective bet with typical small loads running around 2-5 credits per day. This can get very expensive if you don’t manage it carefully with limits.
PostgreSQL will require a migration in the future, so unless you are very cost sensitive, the cost / benefit generally leans in favour of Snowflake.
I have a simple SQL script used to setup Snowflake ready to use for a POC, and I like to use these scripts to track Snowflake credit usage in combination with Dataform assertions.
Distributing/ This is where business users will interact with and judge the success of your system, so to spend your budget on the rest of the components but cut corners on the distribution tool is a bad idea. That said, BI tools can have expensive annual contracts.
Metabase is a great open-source BI tool and should give you a good place to start. The cost jump is quite severe up to Looker / ChartIO, but so is the feature set.
These tools are trickier to migrate from, and so it is reasonable to expect to be locked-in for the mid-term.
Transforming/ This may be premature depending on the level of sophistication of logical transformations required to answer your questions, but at some stage it will make sense to move your transforms to the data warehouse from the BI tool.
The best of breed at this stage is Dataform or dbt. These tools enable software development best practices (git, testing, documentation).
There is relatively little involved in adding this from the start, and significant gains to be had if used to build a logical data model from the start.
I have deployed Metabase successfully with https and nice scalability using these Docker scripts.
In future editions I’ll be diving into the above specifics, stay tuned.
Conclusion
Taking the time to properly implement a reasoned and scalable analytics infrastructure is an axe sharpening exercise with benefits that may compound massively over time. Second-order benefits to aim for include increasing the data proficiency of your team, enabling evidence-based decision making and most importantly, increasing alignment.
Most businesses follow similar patterns, and in survival as in business, preparation is key.

“Give me six hours to chop down a tree and I will spend the first four sharpening the axe.” - Abe
This was a guest post on the Dataform.co blog
Please consider subscribing for more on the subject of data systems thinking
What is group by 1
Who is Matt Arderne