

Dataform and dbt
Dataform and dbt
Some commentary on transformation tooling

Welcome to my third post, one I have wanted to write from the beginning. Getting these posts done isn’t easy, and the time between publishing is a commitment that I undertook rather lightly. Like most good ideas, this one is late, irrelevant, and likely only to be marginally useful. That said, here is a quick rundown on two of the “indicative-of-the-future” SQL tools in data analytics at the moment.
Dataform and dbt, Dbt and dataform
If neither dbt nor Dataform is familiar to you, stop and read my primer post on the modern data analytics stack. This post will still likely be a bit meta unless you are familiar with at least one of these tools. The below two-liner explanation from No frills data warehousing with dbt might be sufficient to get you through.
To use [dbt/Dataform], you only need to be familiar with SQL. The package relies on templating using [jinja/javascript] to enable nifty features like dependency graphs, macros or schema tests. Upon compilation, everything is translated into pure SQL and run on the database’s execution engine. It is quite fascinating how much you can do with such a minimalist tool.

Context
Because I find it interesting, here is my understanding of the history of these tools. Cmd+f to THE TLDR if the what why how and hearsay of technology isn’t your thing.
dbt was born from a common need. Fishtown Analytics, an analytics consulting team, solved their need for a better way to transform data inside a data warehouse. They built a way to manage SQL transformations, as an open-source tool way back in 2016 (epic to git time-travel).
They generously shared their experience through a transformative series of blog posts from their CEO Tristan Handy. He captured many struggling engineer/analysts attention with his “new way” of doing analytics in startups. We, the desperate, listened closely. The message I heard: bring the best of software development to startup data analytics
This was great, but what set this apart amongst the ever-growing set of open-source developer tools was, in my opinion, the “hype house” that was the early dbt slack community.
The Hype House is part of a millennia-old tradition of collaboration among those at the avant-garde of new forms of media, technology, and thought. Outsiders like me have always dismissed the novel as silly, faddish, or worse. When those inside the cutting-edge scenes band together to support, teach, and create with each other, their niche and experimental projects can become the new normal on top of which the next generation builds.
Source (I’ve waited a long time to paste this snippet. Scenius is quite a word, but the article is epic)
The building of this dbt tool was “in the open”, and a community was incubated alongside it. An enthusiastic community. An investible community. The new paradigm was incubated in the dbt slack channel, with contribution, opinion and criticism all weighed and measured in the passionate and growing community.
dbt was first a CLI tool. As is the trend with open-source, evolution is dynamic and open. Dataform was born when a front-end was created by a team of engineers who spotted the opportunity to bring dbt to even less technical analysts through a GUI. Later on, Dataform decided to migrate to a newly built dbt replacement backend for their frontend (also open-source). To match this development, or they had planned to anyway, dbt launched their own GUI SaaS tool (called Sinter, now dbt Cloud for the historians).
Personally, dbt led me to Dataform, and as a consulting data-engineer turned head-of-data, I was drawn by Dataform’s relative ease of getting started. I wanted a tool that I could stick in the hands of a Looker developer and have them hitting the same notes as I was hitting with dbt, with less friction, less cognitive burden, and less fiddle.

So, this post. We’ll briefly run through the most notable differences between dbt and Dataform, how/why to choose, and end with some thoughts on evolution.
Why me? I’ve been working with these tools for a while. I deployed dbt at a company and then migrated to Dataform when Dataform launched. I’ve deployed Dataform with another client and recently worked on a dbt project that used some of the dbt plugins. I now consider both on their relative merits when I make the assessments below.
If you’ve got this far but can go no further, these tools function similarly, with the TLDR worth a look.
The bulk of the value for me has been in having these tools as “ready to use” for data analysts who are strong with LookML, SQL and have exposure to data modelling concepts, but are less familiar with Airflow, CLI tools, Python environments, and git workflows (git undo everything). The singular terror that it is to do anything Python-related on Windows (as a Mac user) has been reason enough to default to avoid having to set someone up with the CLI, enabling git, managing Python dependencies, C++ redistributables, :shock:. Both tools allow developers to move in that direction if they choose, but offer easier onboarding via the SaaS version.
Thus, dbt/Dataform cloud is my primary point of consideration, because that has been my primary interest. Both are extensively used as CLI tools, which for many is the go-to. My focus has been in enabling teams that initially do not have the time/resources to upskill/maintain/support the tech, and so my considerations are within the context of the cloud offering. This may be contentious, but on average the analysts who come from Bizops or something of that nature seem to make for more rounded data analysts, and enabling them is key.
*complete aside, Denodo, a previous employer and data integration technology company, was born out of the need of their consulting team working with large multinationals. They too built a successful enterprise Data Virtualisation tool, which in a way achieves a similar outcome to dbt + Snowflake. In essence a powerful enterprise database multi-plug adaptor, and a SQL DAG builder.
dbt
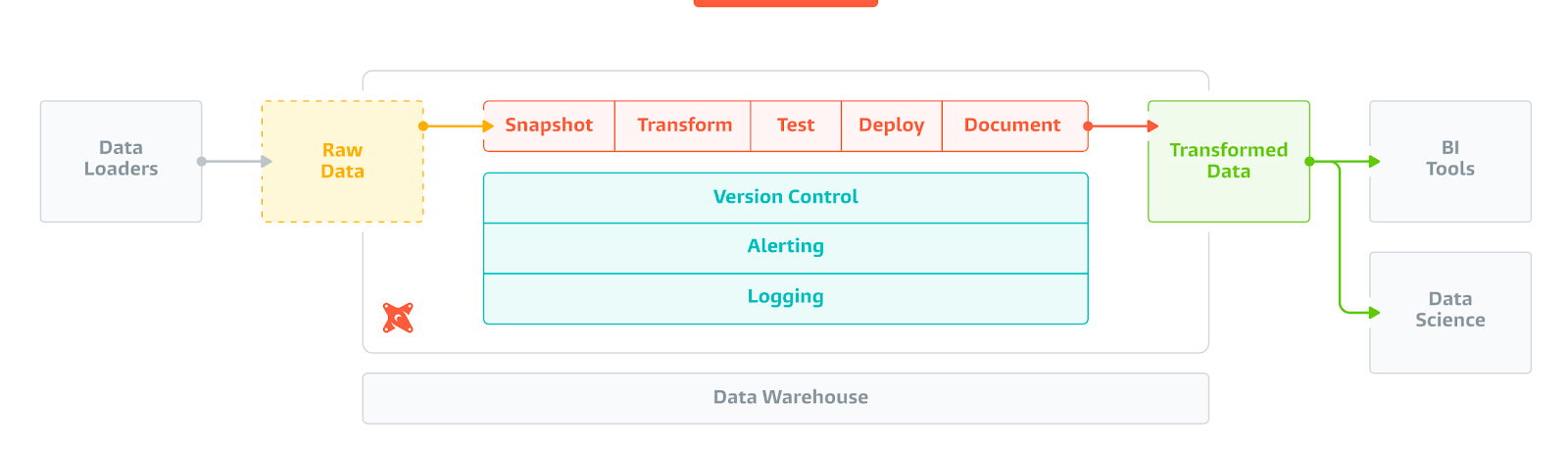
dbt is an open-source tech success story. A dedicated team created the technology they wished they could pay for, built in the open, engaging the community and incubating a “new way” that enthusiasts began to feel very enthusiastic about.
dbt’s strengths lie in the powerful ecosystem they have developed. Illustrative of this are the integrations with tools such as Fivetran, Census, Databricks, that make raw dbt projects pretty mobile and feel like the beginnings of a standard for SQL transformation DAGs.
This ecosystem enables developers to build powerful open-source plugins, available to use and improve. These include useful macros, prebuilt transformations for specific sources, infrastructure management and even some interesting machine learning plugins. The community has built the tools they need on a common standard.
Because dbt is platform-agnostic it feels like an ecosystem rather than a tool alone. Any modern data warehouse is a viable engine to run it, and any modern data tool is likely considering how they can incorporate elements of it to take advantage of the momentum.
When considering dbt cloud, the online version it feels like an online IDE rather than a standalone tool, and according to the founder as of a 1 year ago they’re
in the very early days in improving the developer experience of writing dbt code. The dbt Cloud IDE is still in its infancy, and is only one of the many ways in which we ultimately believe that users will write dbt code that we want to facilitate. source
My take is that this rings true. The usability features are not quite there, a simple example is no autocomplete, which readily exists as a VSCode plugin. [TODO: Validate this is still true (please comment below)]
Dataform
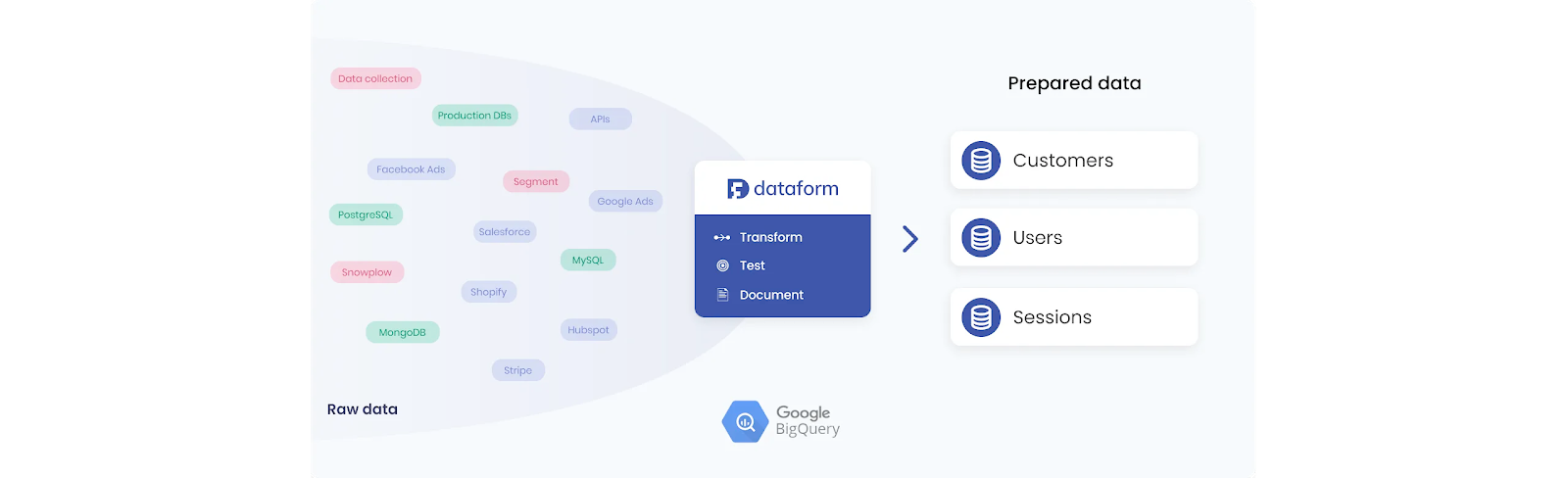
Dataform built a great user interface and my initial impression was that it felt like an easy transition for someone from Looker to orientate and become productive quickly. The user interface has continuously been improved and the backlog of feature requests was quickly moved through, as the team was reactive to suggestions and rapidly added features that provided better prompts, insights and contextual information. Things like prompting about an unbuilt view being referenced, an effective autocomplete, and continuously compiling the SQL to raise errors like typos, glitches, invalid elements introduced prior to execution. These all added to the great user experience of developing.
My least favourite feature is that any templating is done in Javascript (instead of jinja in dbt). Ideally, I’d prefer something closer to Python than either, but jinja feels easier and more intuitive to a non .js type.
[Ammendment] A friend’s opinion, below, which runs counter to mine on the jinja/js thing, and I agree with him, especially if you have a team who know Javascript! My counterpoint is that Looker analysts often find jinja easier to get started. Jinja does get very complicated if you try and do things like cohort funnel analysis.
Your main disadvantage of dataform I actually found to be a great advantage: templating is just javascript. Sometimes jinja starts feeling like a programming language (macros in macros etc.). But that makes a horrible developer experience. In dataform, you can just declare models in a regular old .js file, meaning you’re completely free to build whatever you want. Plus you have all the power and tooling of a mature programming language.
[End Ammendment]
Like dbt, Dataform has benefitted from community-maintained packages.
The most interesting thing about this story is that Dataform was acquired by Google. It seems likely that Dataform will be incorporated into Google’s Big Query data warehouse, I suppose as a “transformation” feature, or perhaps still standalone? This has interesting implications but it does mean that there will be some time getting Dataform integrated. It also means that as a tool it may have less of their historic great responsiveness to user suggestions and demands as they run through the enterprise compliance backlog. This does mean that it will be an easy first choice for Big Query customers to test out this paradigm of data transformation. Sadly, it also means that support for other data warehouses has been sunset.
Implications
The implications of the Google acquisition of Dataform are interesting to me, maybe given my unique experience with both tools, in that it pretty firmly plants dbt as the SQL data transformation standard. This has likely been the case regardless, based purely on momentum and head start that dbt has maintained.
However, had Google maintained Dataform as an independent entity rather than incorporating it into Big Query as an exclusive feature or tool, it may have given Dataform the staging area and resources to properly pose a serious threat as an alternative. This would have been a preferable outcome for me personally. Dataform going exclusively Big Query suggests that the play is likely a more direct threat towards Snowflake’s dominance in the data warehouse space, as the feature race heats up.
From a more practical perspective, the TLDR comes into play. When heading along this road, the first decision you’re likely to make is Big Query or Snowflake (or even Redshift if you have lots of AWS credits… (those are ominous dot dots)) decision, and then if Big Query, deciding between dbt and Dataform. My preference is due to my familiarity with Snowflake, and as a practitioner and consultant, my bet is generally with the coverage and standard-setting dbt.
TLDR
THE TLDR/
Dataform was acquired by Google and is now exclusively GCP, and my guess is that it will be integrating directly into the Big Query platform. If you’re a startup in the GCP ecosystem, then that is compelling. If you like or are already using Snowflake, then Dataform is no longer an option.
dbt has a huge ecosystem built around it, with real momentum benefitting from plugins, integrations and general compatibility across all the analytics tools.
Both tools have a SaaS offering, effectively a cloud IDE + CICD. Great for getting connected and developing quickly. Both happily run a hybrid of cloud IDE and open-source core.
The dbt community has led to many ecosystem “gap fillers” such as spectacles, lightdash, and technically even Dataform itself, all taking the dbt base and extending it or recombining it in different ways.
The modern ELT data stack that no one is going to second guess has Snowflake as the data warehouse, Fivetran doing the ExtractLoad and dbt doing the T for transforms. Note that Snowflake and Fivetran are doing the heavy-lifting, but don’t provide the magic. They are doing the quiet and dependable, probably get taken for granted (other than the price tag), but developing is where insight is captured, and developing is done with dbt.
/ THE TLDR
Evolution

If you jumped to the TLDR and then went further, this is likely where you’d want to stop. The rest is a quick self-indulgent attempt at hypotho-philosophising the evolutionary aspects of software building. Beware!
Watching the evolution of dbt and then Dataform quite closely and with entrenched interest, I have found the dynamics at play interesting, engaging, and commentable. What was also interesting is the entrenched alliances that quickly developed along with people’s preferences or opportunities. Sentiment generally went something along the lines of Dataform ripped the idea off dbt, which I feel is mostly wrong, as the idea isn’t novel, just very well executed and well-timed (IMO, comment below).
I made a meta-take comment on the sentiment in another wonderful slack channel, the comment has now been repurposed for this section, as rambly and raw as it is, I thought captured some of the point:
The tribalism vibe on this was always a weird one for me. us/them always felt counter-productive and tribal [1], but then perhaps that was inevitable. Early dbt felt very much like the beginnings of a tribe: lots of in-jokes, data-eology, new/old. Exciting!
Dataform beginning public life as a dbt front-end ~early 2018 [2] felt pretty confirming.
It did two things for (us) users:
1. affirmed the dbt value prop [3]
2. made using the "new-paradigm" much more accessible to non-techy-data-devs [4]
For reasons, Dataform built their own backend dbt replacement (Google software engineers, I don't know, but they probably do). This change positioned them at odds with one another, but besides that point, the 2 different tools enabled more users to adopt the new paradigm[5].
For me, as a user of dbt and then early dataform, best enabling this new paradigm was a combination of the two, and it was/is great! Collectively this is all a quantum leap for SQL analysts. I'm beyond thrilled that I don't have to use the tools I had to use pre-dbt.
My post-ramble point: I think evolutionary pressure on technology is bloody brilliant for users. Competition is great, iteration should be encouraged. I'm looking forward to someone building an iteration on Looker to this same end.
The evolutionary pressure did two interesting things:
1. It affirmed the need for a SaaS tool for smaller and larger teams. dbt may never have needed to create a user interface, which would have frustrated my team building analytics efforts in smaller tech communities.
2. It created _an alternative_, which is the most important way to add creativity to the space. In real-time users expressed their preferences for different ways of achieving the same goal, in one great experiment.
Interesting parallels to this comparison can loosely be considered in other data tools such as Fivetran & Stitch (closed vs open-source), Snowflake vs Redshift (developer-friendly vs cheaper on paper) and even Tableau vs Looker (old way vs new way).
Both dbt and Dataform now have relatively independent niches, having benefited from the existence of the other. I'm personally glad for having met and got to know the Dataform team and enjoyed being tangentially involved in their growth. The product is great and has been a pleasure to use, and they are nice people who have put a lot of thought into solving my team’s problems.
I think dbt's success in raising lots of VC money is great, they have created many hours of additional output for each hour of development, and more broadly for an enhancement on the thinking in this space, also great people to deal with!
---comment footnotes---
[1] - Tribal ie The Robbers Cave Study
The Robbers Cave experiment studied how hostilities quickly developed between two groups of boys at a summer camp. The researchers were later able to reduce the tensions between the two groups by having them work towards shared goals. The Robbers Cave study helps to illustrate several key ideas in psychology, including realistic conflict theory, social identity theory, and the contact hypothesis. Source (disclaimer - I read about robbers cave this week)
[2] - dataform announcement date ~ May 2018
[3] - dbt on dataform
Hah! This is one of the implications of open-source! ... In my 3-year post, I explicitly called out this likelihood and embraced it
[4] - early dbt-cloud called Sinter, early 2017
[5] See superordinate goals conveniently linked in [1]
Closing

I enjoyed witnessing first-hand the evolution of "a new technology". But I think it probably fairer to call it a recombination, or a reorg. Bottoms up top-down shuffle.
The reshuffle rather than blinding innovation here is made clear by the fact that I could port the code I wrote in 2016 in Denodo’s VQL query language, designed in 2008, which was a large and involved SQL DAG, into something that dbt and Snowflake would happily use. Entirely independently from dbt, and I’d bet mutually unknown, a company created from a users perspective in essence the same way of working. I’m sure from an evolutionary perspective this divergent and now convergent evolution is an interesting quirk.
In that sense, nothing here is “new” enough to interest a computer scientist. The computer scientists I know have an allergic reaction to most of the analytics tooling. Messy and inefficient new ways of doing things, which then become the standards and that look like inflexion points after the fact, and I think for an analyst this change is in progress. Going back to the hype house concept:
Outsiders … always dismissed the novel as silly, faddish, or worse. When those inside the cutting-edge scenes band together to support, teach, and create with each other, their niche and experimental projects can become the new normal
The user is one of the many pressures that drive the evolutionary development of these tools but is best served by choice. Consolidation of technology into profit mode leaves the user’s needs as a low priority, whereas competitive pressure and alternatives put the users at the front. Current trends are about enabling a data analyst turned developer to create as much insight with as little engineering as possible, making it a great time to be an analyst. The users ultimately benefit when the technology scene is in inclusive, collaborative and open mode. Ultimately we are probably due for a period of consolidation mode, but perhaps more on that later.
Please comment if you have any feedback on any of this, I aim to improve with your help.
edit: Somehow the version on my personal backup blog got all the comments
* again interesting aside: Denodo was part of a different paradigm, with virtualisation being the word. Instead of ETL’ing your data into a data warehouse, you’d rather leave it where it lives and query it directly. Whether in a data warehouse, API, transaction database, or many others! A dream for a data architect faced with decades of legacy tech and a desperate need to unify access for analytics and as a data bus. Dremio is now continuing this trend, focussing more on the data lake concept.
Please consider subscribing for more on the subject of data systems thinking
What is group by 1
Who is Matt Arderne
Thanks for this! I always wondered about Dataform since dbt gets all the hype and one wonders how much of it is warranted and how much is just the state of the ecosystem - so the perspective was most welcome. Also, as someone who works professionally and with hobby projects in the GCP analytics space, thinking about how Dataform plays into long-term business positioning is super helpful!
Great article ! Thank you . Any idea when Dataform would be embeded into BQ ?